「人腦如果有個插槽可以植入晶片,
林正。人工智慧
價值道德觀就寫作程式語言;
人工智慧可以接手統治這個世界,
甚至可以試著模擬愛和眼淚」
系統神經科學家,透過紀錄大腦在執行認知功能時的神經訊號,試圖了解大腦訊息處理與運算的機制,這樣對於大腦的探究,剛好和人工智慧的發展相輔相成。不管台北的未來在誰手中,守中的選票要驗多久,人工智慧的未來都在大腦中。
(點播:台北的未來在台鐵便當(博恩版))
2016年3月,由英國倫敦DeepMind公司開發的電腦程式Alpha Go,打敗了世界圍棋冠軍李世乭(이세돌)後,機器學習(machine learning)和人工智慧(artificial intelligence)躍升為全世界眾人皆知的熱門關鍵字,也快速被應用在各行各業,成為各大公司與各國政府致力發展的重點技術領域。
(Alpha Go紀錄片:https://www.youtube.com/watch?v=l9sztL9FQto)
概略上來說,「機器學習」是指透過特定的演算法,讓電腦程式能夠學習執行特定認知功能(例如:圖像辨識、語言翻譯或是下圍棋等)。「人工智慧」,則更廣泛地希望電腦程式,不只能執行認知功能,更能展現人類智慧的整體特色(例如:思考論述、判斷決策、藝術創作,甚至是倫理權衡和情緒經驗)。
大多數機器學習工程師,熱衷於將已開發好的機器學習演算法,透過不同領域的輸入資料拓展其應用範圍。例如將原本使用在行動助理或機器翻譯的語音辨識技術,應用在法庭上證人的證詞真偽判讀。然而,單純透過資料來源拓展應用,就像一間工廠,機器設備都維持不變,只是試著把不同原料丟進同樣的機器中,這樣的發展方式,受到資料的來源和品質而有所侷限。若是想要加強機器學習工廠中的「機器設備」,則需要真正在機器學習背後的演算法上有所創新。
系統神經科學家在研究大腦不同區域的神經訊息處理時,很容易看到人工智慧和神經科學的密切關係。大腦,作為現今唯一能夠展現多重智慧的系統,無時無刻需要接受來自外界環境和內在生理訊息的輸入,經過神經系統的處理和運算,輸出相對應的行為動作或產生情緒經驗——這其中許多特性是目前機器學習演算法所遠遠不足的。因此,從對大腦神經生物機制的觀察和了解出發,可以提供機器學習演算法許多改進的想法。
神經網路革命的重要原理
近年來神經網路(neural network)領域爆炸性的發展,主要歸因於結合了深度學習(deep learning)和強化學習(reinforcement learning)兩個重要概念,而兩者皆源自於早期神經科學研究發展出的概念。
深度學習(Deep Learning)
深度學習(deep learning ),是指近年來,神經網路研究者開始模仿動物神經系統分層的結構,設置許多層虛擬的「神經元」來進行訊息處理。不像早期的神經網路模型,僅使用規則清楚地有限訊息演算,深度神經網路(deep neural network, DNN)在輸入層和輸出層之間,會有許多層負責訊息處理但原理未知的「隱藏層」(hidden layers)。

深度學習大大突破了傳統神經網路模型的學習能力,然而,其中有許多運算原理來自1950-1960年代神經科學界對於大腦訊息處理的認識。例如在物體視覺辨識很常使用的「卷積神經網路」(convolutional neural network, CNN),其中包含了「非線性訊息傳導」 (nonlinear transduction)、「除式標準化」(divisive normalisation)等運算原則,源自於1981年諾貝爾生理醫學獎得主 David Hubel 與 Torsten Wiesel 早年利用電極對哺乳類初級視覺皮質(V1)進行單神經元紀錄(single neuron recording)一系列的研究結果 (Hubel and Wiesel, 1959)。
有趣的是,即使沒有事先人為設定每一層神經層處理訊息的詳細規則,經過大量資料訓練的人工視覺辨識系統,也會表現出和動物的視覺系統類似的階層處理模式:先辨識輪廓、再辨識局部特徵、最後才是物體的辨認。(Grigsby, 2018)這樣的相似性,支持了深度神經網路的生物可能性(biological plausibility),也意味著在其他的認知系統,只要模仿大腦的神經結構,其間的資訊交流就有機會透過資料的反覆訓練,達到模擬大腦的訊息處理方式。
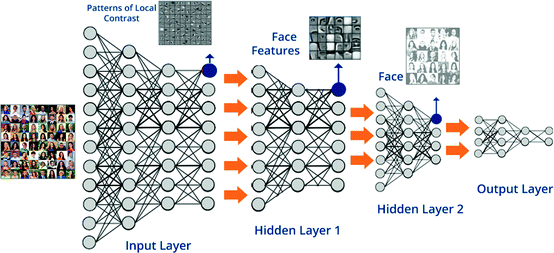
強化學習(Reinforcement Learning)
強化學習(reinforcement learning),一個系統透過適當的回饋機制(feedback),進行試誤學習(trial-and-error),不斷改進而增進運算表現的學習機制。這就像是在小孩子在探索未知的世界一樣,充滿好奇心,什麼都想要嘗試,透過自身的經驗進行學習,不斷修正下次遇到類似狀況的反應。強化學習中最重要的回饋訊號,首次由我的指導老師 Wolfram Schultz 在獼猴中腦的多巴胺神經元中被記錄到(Schultz et al., 1997),直到現在,我們已經知道,從果蠅到人類的大腦中都存在類似的學習機制。此實驗的結果和同時期由 Sutton和Barto發展出來的強化學習演算法相互輝映,也讓我們逐漸了解到大腦中不同腦區,在強化學習演算法中扮演的對應角色。(Sutton & Barto, 1998; Doya, 2008)
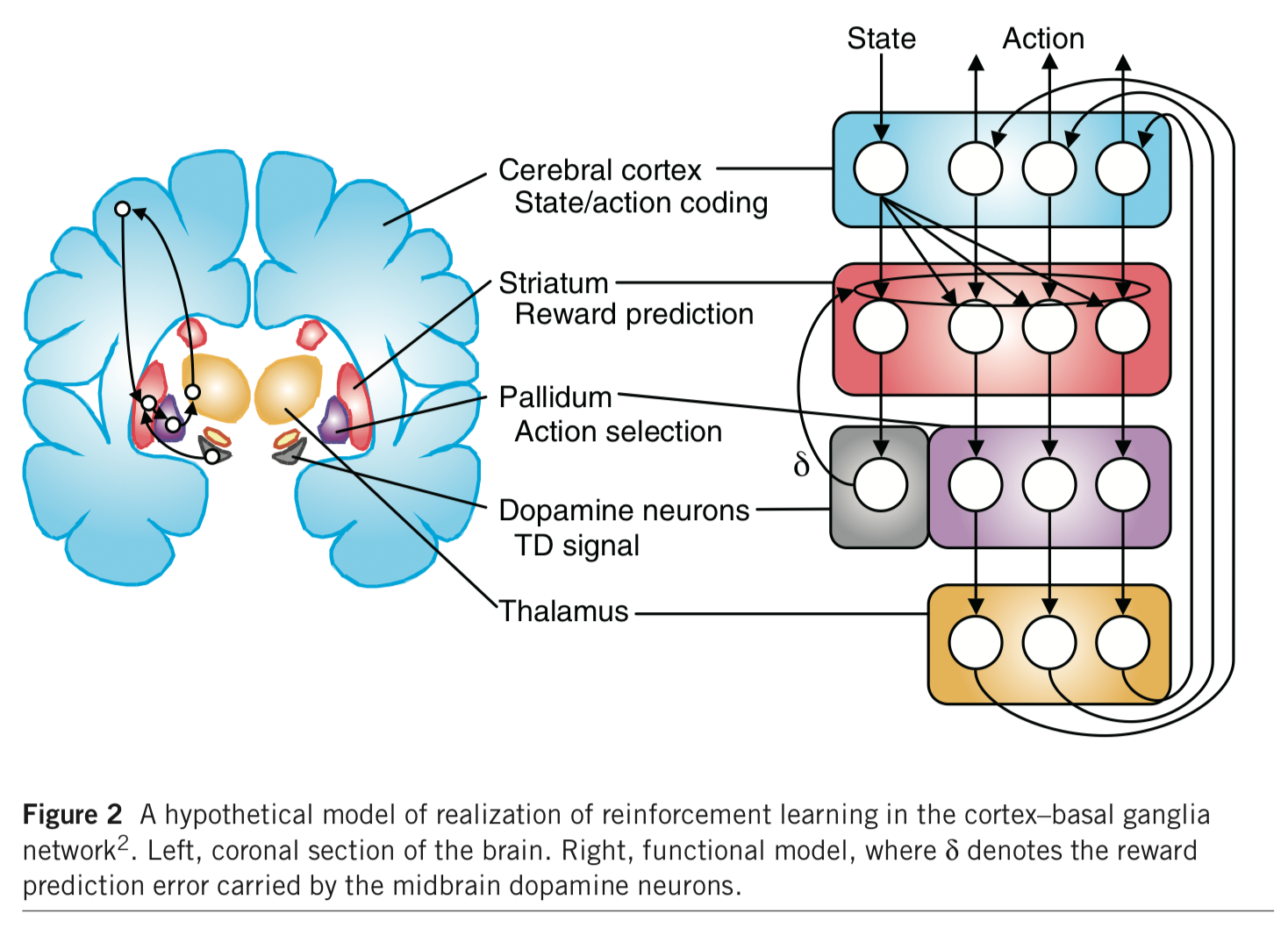
(Nat Neurosci. 2008 Apr;11(4):410-6.)
機器學習演算法的改進空間:腦科學的觀點
最新的神經生理觀念尚未完全引入
當前機器學習演算法雖然使用了許多腦科學的概念,促進了前所未有的突破性發展,然而,其使用的概念大多是1950-60年代的發現,突飛猛進的神經科學近年來對於神經資訊的處理方式,還有許多可以提供機器學習發展的新方向。舉例來說:大腦中具有多層次的階層學習系統(hierarchical learning system),人類不一定要透過試誤學習才知道熱水會燙傷,透過觀察學習(observational learning)和規則學習(rule-based learning)的結合,大腦無時無刻都能夠對環境進行預測,透過前額葉(prefrontal lobe)使我們預見對自己行為的後果並且監測自己行為的執行,只要任何改變預測結果的事件發生時,就可以回饋給系統進行學習。例如早上出門時,看見行人手中拿著傘,即使還沒有看到下雨,也不需要親自被雨淋濕,大腦就可以預測很有可能等下走出去會下雨,本來如果決定不帶雨傘的人,馬上就可以透過「看到別人拿傘」的視覺回饋,直接進行學習,了解下次遇到類似的情況,應該要帶著雨傘出門。
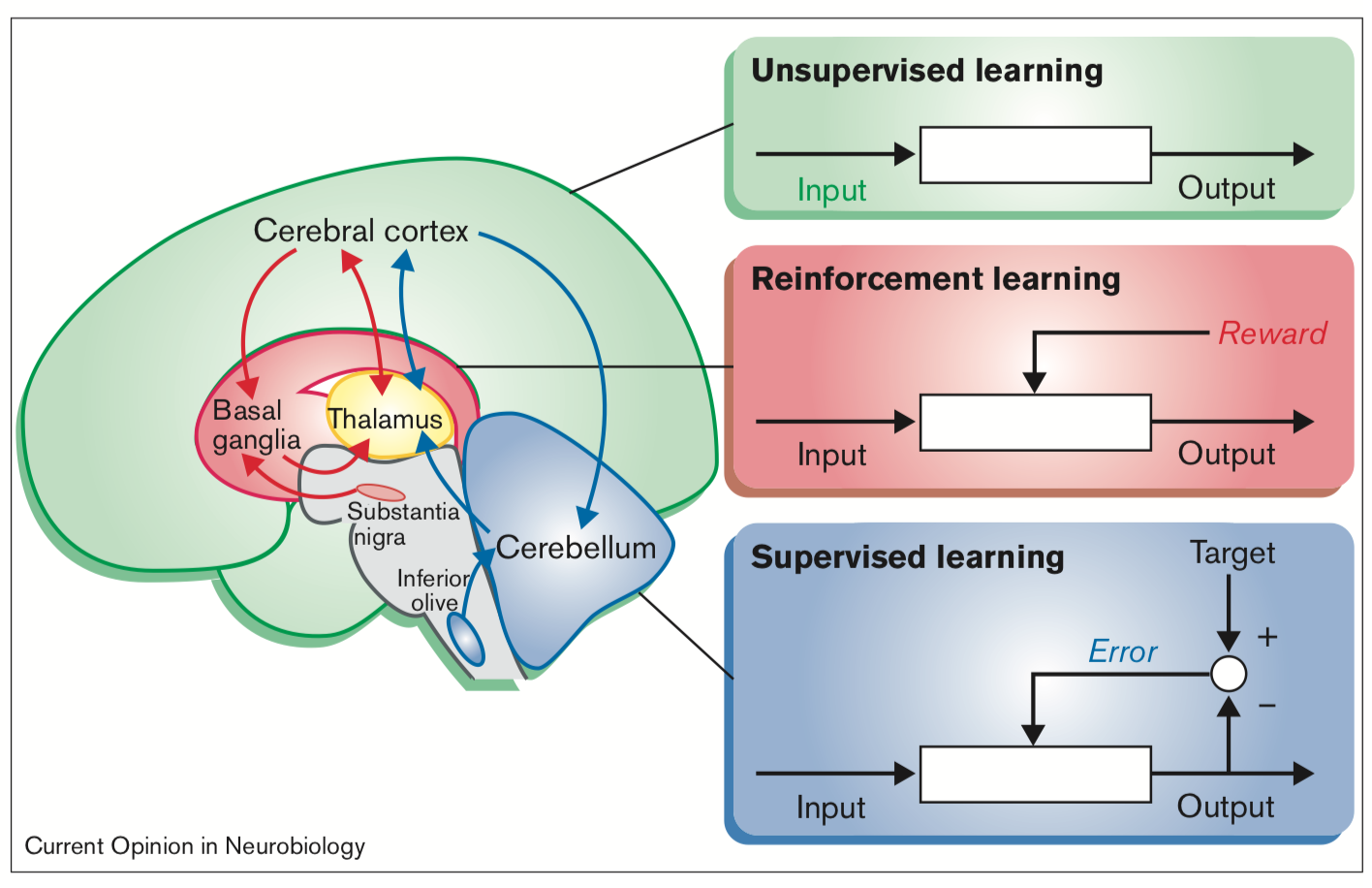
這樣「學習如何學習」(learning to learn)的超強化學習(meta-reinforcement learning)系統可以試圖解決目前機器學習常見的「毀滅式遺忘」(catastrophic forgetting)的問題,使得神經網路不會再一開始學習新的任務時,新的回饋就馬上使神經網路忘記先前學習過的任務(Wang et al., 2018)。這種「轉換學習」(transfer learning)的能力,讓學過直排輪的人很快就可以學會溜冰刀,擅長學習的人,可以利用先前的學習經驗,更有效率地去學習其他事情,這是目前機器學習演算法很難達到的目標,也是要達到所謂「強人工智慧」(artificial general intelligence, AGI)必須要解決的重要問題之一。
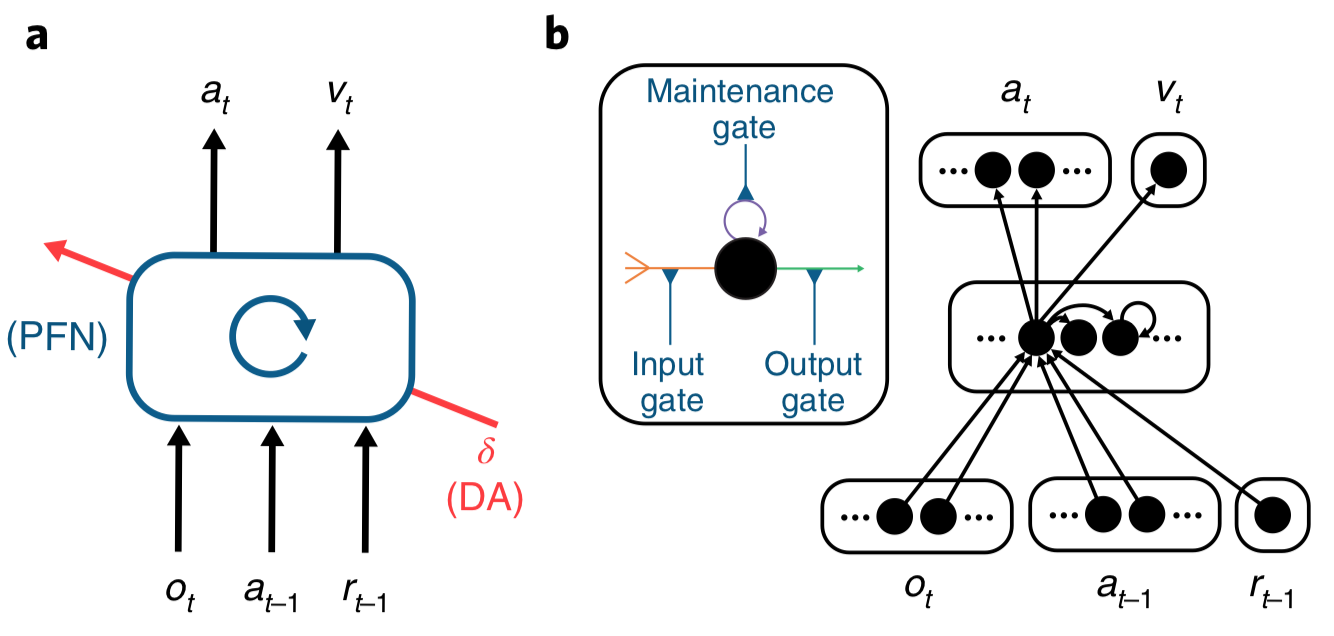
Nat Neurosci. 2018 Jun;21(6):860-868.
海馬迴功能對演算法的改進
近年來,許多機器學習演算法的改進,主要建立在將海馬迴的功能加入神經網路當中。研究發現海馬迴在休息時,會對短期發生的事件記憶(episodic memory)進行重新播放(memory replay),藉此將記憶訊號逐漸轉換到大腦皮質(Kumaran et al., 2016; McClelland et al., 1995)。此機制可以解釋早期透過觀察海馬迴損傷或是海馬迴遭到切除的病人,無法將短期記憶儲存變成長期記憶的現象。這樣的技術也應用在2006年 DeepMind 公司設計用來破解 Atari 復古電玩遊戲的Deep-Q-Network(DQN)中。透過「經驗重播」(experience replay),即使只有一次的有限經驗,只要還「記憶猶新」,也可以直接將策略應用在後來面對到的情境,如此達到比單純只用強化學習更有效率的學習方法。此外,2004年諾貝爾生理醫學獎得主 John O’Keefe 發現小鼠的大腦中,能夠將外界環境的資訊投射在海馬迴神經元的空間分佈上,形成一張腦內的對應地圖(O’Keefe, 1976)。這些「位置神經元」(place cells)可以提供大腦對於空間抽象想像的平台,也更能支持模擬學習(simulation-based learning)的神經機制。
「情緒」:機器學習演算法缺少的重要拼圖
未來,我認為機器學習乃至於人工智慧一個很有潛力的突破方向,在於如何將「情緒」的神經模組加進演算法當中。情緒並非像一般人所認為,只會干擾理性思考的運作。事實上,有許多間接的證據顯示,情緒其實是思考與決策「必要」的條件之一。然而,神經科學界目前對於情緒如何產生,以及情緒如何在不同階段影響思考與決策的訊息處理,了解並不多。我之後的實驗也會碰觸到相關的議題,希望能從根本的神經生理學,對於情緒處理、社會互動以及決策行為有更多了解,期許有一天能和現有的演算法結合,增進其學習表現、也能對人類各種正常和異常的情緒現象有更多了解,等研究成果發表後,再好好來寫篇文章分享一下心得。
結語
雖然人工智慧與機器學習領域,對於演算法是否需要學習大腦的機制有正反兩面不同的聲音,但目前的演算法和人類智能相比,仍有許多可以改進的空間,因此,不妨將大腦的機制當作創造演算法的「靈感來源」,也同時比較生物機制和程式運算的異同,以期能透過不同領域的切入觀點,共同解開人類智能的奧秘。
參考資料
- Hubel D. and Wiesel T. Receptive fields of single neurones in the cat’s striate cortex. J Physiol. 1959 Oct;148(3): 574–591.
- Grigsby S.S. Artificial Intelligence for Advanced Human-Machine Symbiosis. In: Schmorrow D., Fidopiastis C. (eds) Augmented Cognition: Intelligent Technologies. AC 2018. Lecture Notes in Computer Science, vol 10915. Springer, Cham
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997 Mar 14;275(5306):1593-9.
- Sutton, R. & Barto, A. Reinforcement Learning: An Introduction(MIT Press, 1998)
- Doya K. Modulators of decision making. Nat Neurosci. 2008 Apr;11(4):410-6.
- Doya K. Complementary roles of basal ganglia and cerebellum in learning and motor control. Curr Opin Neurobiol. 2000 Dec;10(6):732-9.
- Wang JX, Kurth-Nelson Z, Kumaran D, Tirumala D, Soyer H, Leibo JZ, Hassabis D, Botvinick M. Prefrontal cortex as a meta-reinforcement learning system. Nat Neurosci. 2018 Jun;21(6):860-868.
- Kumaran D, Banino A, Blundell C, Hassabis D, Dayan P. Computations Underlying Social Hierarchy Learning: Distinct Neural Mechanisms for Updating and Representing Self-Relevant Information. Neuron. 2016 Dec 7; 92(5): 1135–1147.
- McClelland JL, McNaughton BL, O’Reilly RC. Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory. Psychol Rev. 1995 Jul;102(3):419-457.
- O’Keefe J. Place units in the hippocampus of the freely moving rat. Exp Neurol. 1976 Apr;51(1):78-109.
